Many popular language models today are created by large, for-profit technology companies and serve the goals of these corporations. Can we envision a co-operative language model that challenges existing notions of how technology is created and who it can serve?
What would a language model look like if it was created by writers and to serve their creative community?
How would we govern a language model run for and by creative writers? This project arose from a research study we conducted on how creative writers reason about the use of their writing as training data for large language models. Check out the published paper or our blog version online.
Large language models (LLMs) present significant ethical concerns across a number of dimensions—from resource overuse to labor exploitation to intellectual theft. At the same time, LLMs have also demonstrated potential as artistic, pedagogical, and humanistic tools. Yet, as our previous study revealed, the problems with available LLMs make many people unwilling to use them, even if such models are humanistically interesting.
There are ongoing efforts to reign in corporate LLMs, such as lawsuits to prevent the unconsensual use of writing as training data, and calls for collective refusal. There are also efforts to document and create more ethically-minded LLMs, such as the European Open Source AI Index to track how open LLMs truly are and OLMo, a state-of-the-art, truly open language model with inspectable training data. These are important efforts, but can remain distant for specific communities that may want to engage with this technology directly and on their own terms.
Our aim is to shepherd writer-led and contributed language models, where “creative writing as training data” is well-documented, full consent is provided by all contributing writers, and use cases are recorded and shared with community members. The training datasets and models will be guided by a community board. Such models would provide an ethical LLM option and be designed to prioritize community values like diversity and creativity.
Starting in February 2025, we ran a series of workshops to envision what a community-run creative language model could look like through the lens of metaphors. These workshops seeded the analysis of “metaphors for models”.
Below we summarize the workshops as a whole, and provide our materials for those interested in running their own.
Through these workshops, we have collectively generated over 200 “metaphors for models” – projects, activities, collectives, locations that may make good metaphors for how to create and run a language model.
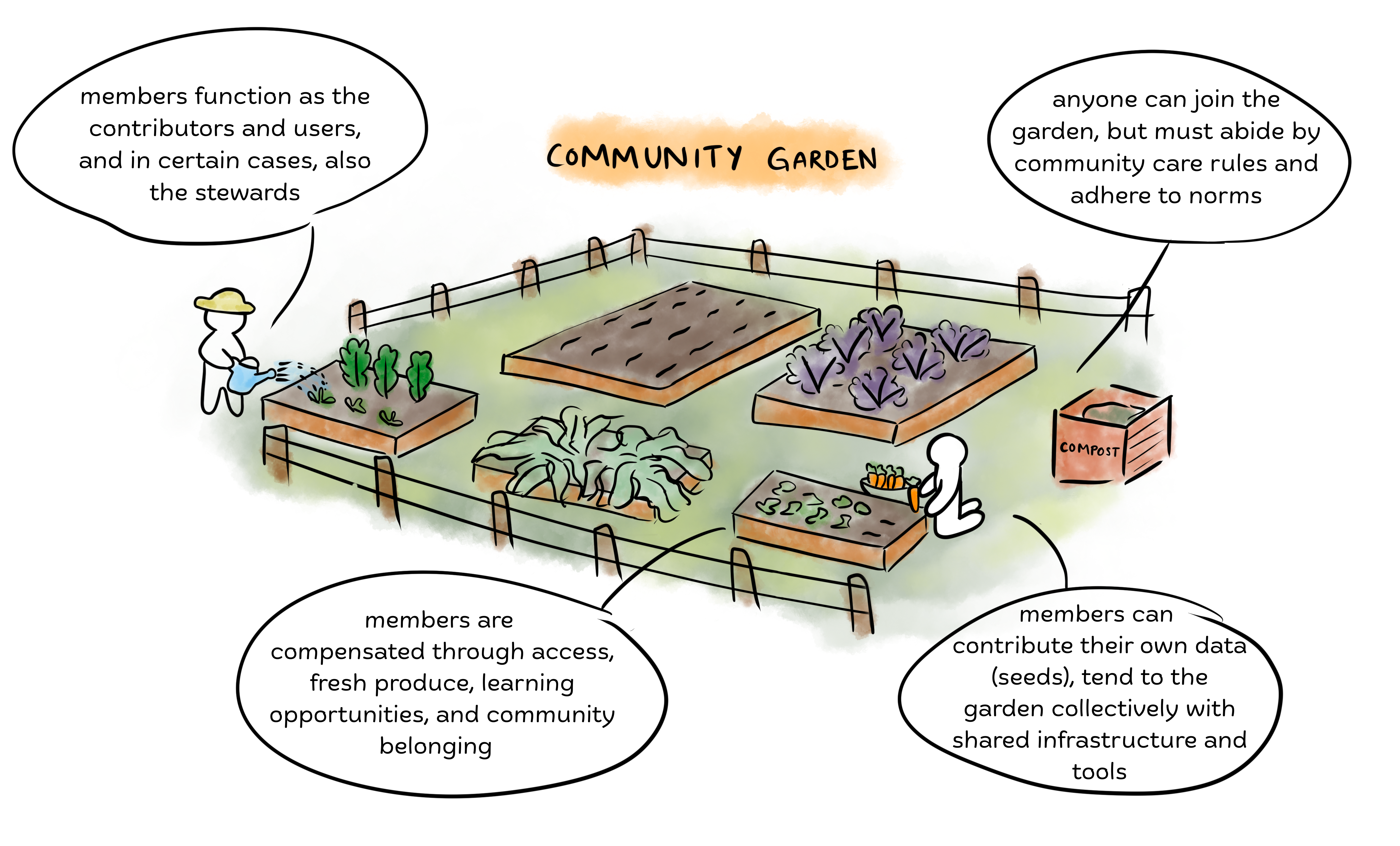
For instance, what if a language model was like a community vegetable garden? Or a seed bank? Or the bathroom in a dive bar? Across the workshops, metaphors helped participants reason about data contribution, access, stewardship, norms, credit, and shared infrastructure.
To participate in the writing pilot or run your own workshops, contact Carly at cschnit1@jh.edu. For model training interest, contact Katy at katy.gero@sydney.edu.au. For other research collaborations, contact Alicia at axguo@uw.edu.